Sampling Settings
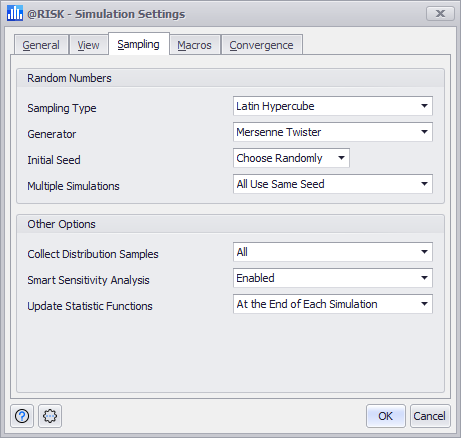
Figure 1 - Simulation Settings Window - Sampling Tab
The Sampling tab of the Simulation Settings window (Figure 1, right) includes two options groups:
See Iterations and Simulations for more information on sampling
Random Number Options
These settings control the methods by which @RISK will generate random values for distribution samples for all @RISK input functions.
Please note: these options can have a significant impact on the results of a simulation! They should only be modified if the effects of any changes are well understood.
Other Options
The 'Other Options' settings determine how (or if) @RISK collects and stores distribution sample values, among other settings related to distribution samples. Collection of distribution sample values and their statistics aids in analysis through Simulation Sensitivities and Simulation Scenarios by preserving the values upon which various other statistics can be generated. Additionally, saved sample values can be viewed in the Simulation Data window (e.g. for debugging purposes).