Fit Copula
Similar to input distributions, a copula can be fit to an existing data set (a correlation does not require fitting as it always utilizes the elliptical gaussian type). The fitted copula configuration can then be used with other inputs.
The fitting process must include at least two columns of data (two sets of data to be correlated); when the fitting process runs, @RISK will test each of the selected copula types against the data to determine which copula would reproduce sample values most similar to the existing data. Once the fitting process is complete, @RISK will display the results in the Copula Fit Results window.
To fit a copula to an existing set of data, select at least two columns of values, click the lower half of the Correlations button, and select Fit Copula.
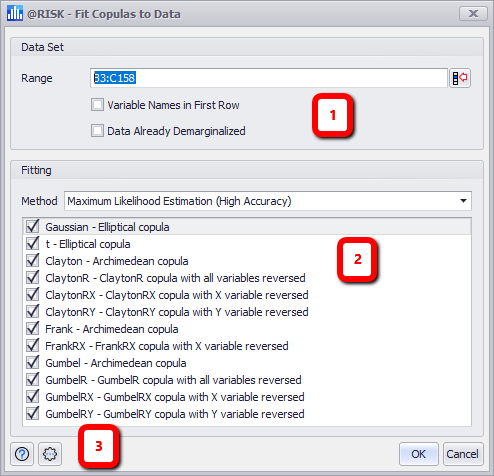
Figure 1 - Fit Copulas to Data Window
Fit Copulas to Data
The Fit Copulas to Data window consists of the following primary sections:
- Data Set - Details of the data to be to be included in the fit. See below for more information.
- Fitting - Configurations for the method of fitting and the copula types to be tested.
- Command Buttons
Data Set
The Data Set panel includes the details of the data set to be used in the fitting process.
Fitting
The fitting process uses the selected data set and tests all copula types that have been selected for fitting against the data. The method for determining how well a copula fits to the data can also be selected.
When using any of the fitting methods, select the copula types to be tested by checking the box next to the copula name.
Select a fitting method from the Method pull-down menu. The options include:
Command Buttons
The Command Buttons of the Fit Copulas to Data window include:
-
 Help - Open help resources (online or local, based on @RISK settings); the Help Button for more information.
Help - Open help resources (online or local, based on @RISK settings); the Help Button for more information. -
 Settings/Actions - Window-specific seettings and actions. The Fit Copulas to Data options are:
Settings/Actions - Window-specific seettings and actions. The Fit Copulas to Data options are: